수많은 스트림 데이터를 안정적으로 구독하기 위한 시스템 설계 방법은 정말 다양하다.
이 글에서는 대용량 결제 데이터 스트림을 처리하기 위해 우리가 어떻게 설계를 했는지 서술하겠당
Listener vs Consumer
Kafka를 사용하기 위해 다음 라이브러리를 사용했다.
https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka
해당 라이브러리는 @KafkaListener 라는 강력한 어노테이션을 지원해준다.
일반적으로 Spring 환경에서 Kafka 토픽을 구독하기 위해선 두 가지 방법을 떠올릴 수 있다.
1. @KafkaListener 사용
2. 주기적인 스케쥴링을 통한 Consumer.poll 사용
@KafkaListener가 제공해주는 에러 처리, 개발의 간편함 그리고 가장 중요한 멀티 쓰레드 환경에서의 concurrency 와 같은 기능의 매력에 사로잡혀 이를 선택했다.
컨슈머의 쓰레드 풀
@KafkaListener 를 선택한 가장 큰 이유는 concurrency 기능을 제공해주는 점이다.
이는 브로커가 서버에 할당해주는 파티션들을 여러개의 컨슈머 쓰레드에서 병렬적으로 구독할 수 있는 기능이다.
하나의 서버 프로세스에서 여러개의 컨슈머 쓰레드를 사용해 여러개의 파티션을 구독할 수 있다면 정말 좋을 것이다.
Consumer의 poll 기능과 직접 구현한 멀티 쓰레딩 기능 접목해 사용해도 전혀 문제가 없지만, concurrency 기능을 지원해주는데 굳이 직접 힘들게 구현할 필요가 없다.
더불어, KafkaListener는 컨슈머의 쓰레드가 소속될 쓰레드 풀을 커스텀하게 설정도 할 수 있다.
kafkaListenerContainerFactory.setConcurrency(WorkerConfig.KAFKA_THREAD_POOL_SIZE);
kafkaListenerContainerFactory.getContainerProperties().setListenerTaskExecutor(streamWorkerExecutor);
위와 같은 간편한 딸깍을 이용해 컨슈머 병렬처리 기능을 사용할 수 있다.
여기서 가장 중요한 것은 concurrency 설정 값과 커스텀하게 지정한 쓰레드풀의 사이즈를 어떤 관계성에 의해 설정할지 정하는 것이다.
위 코드에서 설정하는 concurrency는 몇개의 컨슈머 쓰레드를 운용할지 선택할 수 있는 값이다.
만약 이 값이 커스텀으로 지정한 쓰레드 풀보다 작다면 idle한 커스텀 쓰레드가 생길 것이고, 그렇지 않다면 실제론 커스텀 쓰레드 수만큼만 컨슈머가 생길 것이니 의미없는 값이 될 것이다.
따라서, concurrency는 현재 운용중인 쓰레드 수와 정확히 일치하는 것이 가장 이상적이다.
더 나아가, 이 값이 현재 서버가 할당받은 파티션수와도 일치하면 한 쓰레드가 하나의 파티션을 구독하고 유휴상태의 쓰레드가 없게 되는 것이니 최상의 구조일 것이다.
서버의 자원이 충분하다면 단일 서버를 띄운채로 concurrency 값과 커스텀 쓰레드 풀의 사이즈를 토픽의 파티션 개수만큼 설정하는 것이 최선의 방법이지만, 한 서버 프로세스가 감당할 수 있는 최대의 쓰레드 풀을 고려해서 설정해야 한다.
따라서 우리는 concurrency 값을 최대한 이상적인 값으로 맞추기 위해 해당 식을 적용했다.
P : 해당 토픽의 파티션 개수
N : 멀티 서버 환경에서의 서버 프로세스 개수
C : concurrency 설정 값
T : 해당 서버에서 컨슈머 쓰레드에 할당할 수 있는 최대 쓰레드 개수
C = Min(T, Max(P/N, 1))
브로커가 모든 서버에 최대한 균등하게 파티션을 배분했다는 가정 하에 한 서버에 할당 되는 파티션수와 해당 서버에서 컨슈머 쓰레드에 사용할 수 있는 최대 쓰레드 수 중 더 작은 값을 사용한다.
수동커밋과 오프셋 리셋 정책
@KafkaListener 의 또다른 장점은 메시지의 커밋을 자동을 지원 해준다는 점이다.
다만 우리는 커스텀하게 메시지의 커밋을 처리해야 해서 이 기능을 사용하지 않고 수동으로 커밋을 관리하는 설정을 적용했다.
kafkaListenerContainerFactory.getContainerProperties().setAckMode(AckMode.MANUAL);
AckMode 에는 여러가지가 있는데, 해당 문서를 참고하여 자신에게 맞는 방식을 사용하면 된다. 기본값은 BATCH 다.
또한, 커밋과 관련된 auto.offset.reset 이라는 설정값도 존재한다.
이는 컨슈머가 파티션을 읽기 시작했을 때 유효한 오프셋이 없는 경우 어디서부터 메시지를 읽게 할 것인지에 대한 설정이다.
여기서 유효한 오프셋이란 해당 파티션에서 가장 최근에 커밋된 메시지를 의미한다.
해당 파티션에 커밋된 메시지가 존재하지 않는 경우는 해당 컨슘 그룹으로 파티션에 최초로 접근하거나 이전의 처리에서 오프셋을 한번도 커밋하지 않았을 때 발생한다. 때문에, 일반적인 상황에서는 컨슘 그룹을 교체하거나 서버를 새로 띄울 때 해당되기에 평상시에는 중요하지 않은 값이다.
중요하지 않아도 알고 넘어가자.
| latest | 가장 최근의 메시지부터 구독 |
| earliest | 가장 오래된 메시지부터 구독 |
| none | 예외를 발생시키고 처리 중단 |
우리는 이 서버를 새로 배포하기 전, 이미 스트림에 데이터가 들어오고 있던 상황이라 earliest 정책을 사용했다.
유효한 오프셋이 존재하는 일반적인 상황에선, 컨슈머가 파티션에 진입할 경우 가장 최근에 커밋된 메시지의 다음 오프셋부터 읽기 시작한다.
에러 처리에 대한 고찰
스트림 메시지를 처리할 때 가장 주의깊게 살펴볼 부분은 메시지를 처리하는 도중 발생한 에러에 대한 처리이다.
일반적인 처리 방식은 큐잉 메시지에서 사용하는 데드레터 방식이다.
스트림 메시지를 처리하다 오류가 발생하면 일단 오프셋을 커밋한 후, 큐와 같은 공통 미들웨어에 메시지 정보를 저장한 다음 특정 시점에 이곳에 저장된 메시지를 재처리 하는 것이다.
위 방식에서 몇가지를 수정했는데, 일단 재시도가 없다.
서비스 로직 특성상 해당 메시지에 에러가 발생하면 재처리해도 같은 에러가 발생할 확률이 매우 높다. (사내 타 서비스 의존도 존재)
때문에 메시지를 재처리 하지 않고, 에러가 발생하는 즉시 메시지를 커밋하고 재처리를 위해 미들웨어에 정보를 저장한다.
미들웨어는 레디스를 사용했다. 새롭게 SQS나 RabbitMQ 같은 인프라를 구축하기도 귀찮았고, 사용하고 있는 레디스의 용량이 꽤 여유가 있었다.
결과적으로 스트림 메시지의 대한 에러처리 프로세스는 다음과 같다.

1. 스트림 메시지 에러 발생
2. 오프셋 커밋 후, 해당 메시지 정보 레디스에 저장
3. 해당 메시지를 재처리 할지, 그냥 넘길지 판단 후 실행 (백오피스)
4. 재처리를 선택한 경우 토픽에 새로운 메시지로 재발행
위 프로세스가 가능한 이유는 해당 토픽을 컨슘하는 주체는 우리로 유일했기 때문이다.
만약 해당 토픽을 다른 서비스도 구독하고 있다면 재처리에 의해 중복되어 재발행 되는 메시지에 대한 처리의 필요성을 고지해야한다.
만약 어떠한 이유로 인해 해당 토픽의 중복된 메시지의 재발행이 금지된다면, 굳이 스트림에 넣지 않고 직접 처리해도 상관 없다. 조금 귀찮을뿐..
파티션의 리밸런싱
개발중 대부분의 원인 모를 이상한 동작은 대부분 리밸런싱 때문이었다.
우리는 Kafka 설정에서 컨슈머의 동적 멤버십 정책을 사용했다. 이는 특정 컨슈머에 문제가 생기면 해당 컨슈머에 할당되었던 파티션을 다른 정상 컨슈머에 할당하는 방식이다.
반대로 정적 멤버십은 말 그대로 컨슈머에 지정된 파티션을 고정하는 방식이다.
정적 멤버십은 컨슈머에 파티션이 고정되기 때문에 관리가 편하고, 파티션 리밸런싱이 초래하는 오버헤드를 줄일 수 있는 반면, 특정 컨슈머의 연결 실패 발생 시 재시도 이외에 적절한 해결방안이 없기 때문에 리스크가 명확하다.
따라서 동적 멤버십을 사용했다.
혹여나 자신의 서비스에 정적 멤버십을 적용해야 한다면 Kafka 설정에서 다음과 같이 그룹 인스턴스를 지정해주면 된다.
configs.put(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "MY GROUP INSTANCE ID");
파티션의 리밸런싱은 다음과 같은 상황등에 발생한다고 알려져있다.
- 컨슈머가 새롭게 추가되거나 기존 컨슈머가 삭제될 때
- 컨슈머의 물리적인 문제 또는 네트워크 이슈로 인한 브로커 응답 실패
- 토픽의 파티션 수 변경
- 카프카 클러스터 구성 변경
서버 배포를 제외하면 일반적으로 마주하기 쉽지는 않다.
그나마 마주할 수 있는 상황은 두번째 인데, 이는 주로 Polling 타임아웃에 의해 발생한다.
Kafka 설정에는 대표적으로 세 종류의 타임아웃 설정이 존재한다.
컨슈머는 카프카 브로커에게 하트비트를 보내고 토픽에서 메시지를 Polling 하며 자신의 건재함을 알린다.
| session.timeout.ms | 컨슈머와 브로커 사이의 세션 타임아웃을 의미한다. 이 시간동안 컨슈머의 하트비트가 브로커에게 도달하지 않으면 그룹의 코디네이터는 해당 컨슈머에 문제가 발생했다고 판단한 이후, 그룹에서 제외시킨다. 이는 파티션 리밸런싱을 초래한다. |
| heartbeat.interval.ms | 컨슈머가 브로커에게 어느 주기로 하트비트를 보낼지 설정한다. 세션 타임아웃의 1/N로 정한다. 쉽게말해 세션 타임아웃동안 컨슈머의 하트비트 전송 기회를 N번 주는데 이 기회를 모두 놓치면 세션 타임아웃이 발생한다. 보통 N=3으로 지정한다 |
| max.poll.interval.ms | 컨슈머는 하트비트만 보내는 헬스체커가 아니다. 토픽에서 메시지를 Polling 해서 처리하는 것이 주 목적인데, 혹여나 어떤 컨슈머가 메시지를 Polling하지는 않고 하트비트만 보내는 괘씸한 녀석이라면 이를 감지하고 자격을 박탈해야 한다. 해당 주기동안 컨슈머가 토픽에서 메시지를 Polling 하지 않으면 컨슈머 장애로 분류하고 그룹에서 제외한다. 이 역시 파티션 리밸런싱을 초래한다. |
위 값 모두 Kafka 설정에서 커스텀하게 바꿀 수 있다.
configs.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, heartbeatInterval);
configs.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
configs.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, maxPollInterval);
우리는 모두 기본 설정값을 사용했다. 기본값은 라이브러리에 따라 다를 수 있다.
(세션 10초, 하트비트 3초, 폴링 5분)
동적 멤버십 정책을 선택했다면 파티션의 리밸런싱으로 인한 문제를 대비하고 서비스 로직에서 적절히 처리해야 한다.
예를 들어 다음과 같은 경우가 있다. 동일 컨슘 그룹 내 컨슈머 A, B, C가 있다고 가정한다.
| 컨슈머 A | 컨슈머 B | 컨슈머 C |
| 파티션 1,2 할당 | 파티션 3 할당 | 파티션 4 할당 |
| 1번 파티션 1번 오프셋 메시지 처리 (커밋 O) |
3번 파티션 1번 오프셋 메시지 처리 (커밋 O) |
|
| 1번 파티션 2번 오프셋 메시지 처리 (도중 원인 모를 지연 발생) (커밋X) |
||
| Polling 타임아웃으로 인한 파티션 리밸런싱 | ||
| 파티션 1,3 할당 | 파티션 2,4 할당 | |
| 지연 발생 이후 이전 작업 처리 (1번 파티션 2번 오프셋) (커밋 불가) |
1번 파티션 2번 오프셋 메시지 처리 (커밋O) |
|
위 시나리오에 따르면 1번 파티션의 2번 오프셋 메시지는 두 서버에서 중복 처리 될 것이다. 실제로 테스트를 했었는데 중복처리 되는 점을 확인했다.
이때 컨슈머 A의 쓰레드에서 이 메시지를 처리한 후, 커밋이 실패한다. 현재 컨슈머에 할당된 파티션과 다른 파티션의 메시지이기 때문이다.
다음과 같은 메시지를 볼 수 있다.
Failing OffsetCommit request since the consumer is not part of an active group
메시지 중복처리에 민감하지 않다면 그냥 둬도 상관없다. 하지만 처리할 수 있으면 더 좋지 않겠는가
따라서 우리는 현재 자신에게 연결된 파티션의 메시지가 아닌 경우 메시지를 처리하지 않는 방식으로 구현했다. 메시지를 커밋하지도 않을거기 때문에 리밸런싱으로 인해 옮겨간 컨슈머가 처리해줄 것이다.
일단 메시지를 처리하기 전, 자신에게 할당된 파티션을 파악해야 한다.
@KafkaListener(topics = "${stream.kafka.topic}", groupId = "${stream.kafka.group.id}")
public void receive(ConsumerRecord<String, String> record, Acknowledgment acknowledgment, KafkaConsumer<String, String> consumer)
{
Set<TopicPartition> topicPartitions = consumer.assignment();
}
위 처럼 카프카 리스너의 함수의 Consumer 파라미터 받아 현재 컨슈머에 연결된 파티션 정보를 얻을 수 있다.
그럼 메시지를 처리하기 직전 현재 처리하려는 메시지의 파티션 정보와 이를 비교하면 쉽게 해결할 수 있겠구나?
그러지 못한다.
- 컨슈머 A에 1번 파티션 할당 / 이때 Comsumer 객체엔 1번 파티션 정보가 저장됨
- 컨슈머 A가 1번 파티션 2번 오프셋 폴링
- 메시지를 처리하기전 지연 발생 후 파티션 리밸런싱 / 1번 파티션 다른 컨슈머로 이동
- 지연 이후 메시지 처리를 위한 파티션 정보 비교 (Consumer엔 1번 파티션이 아직 저장되어 있으므로 정상으로 판단)
- 메시지 처리 후 커밋 시도 / 하지만 실제 컨슈머에 연결된 파티션이 아니므로 커밋 실패
위 처럼 Consumer의 정보는 실시간 커넥션 정보가 아니기 때문에 이로는 해결할 수 없다.
파티션이 할당/해제 될 때마다 어딘가에 공통으로 저장해야한다.
짬통 = 레디스
Spring Kafka 라이브러리를 사용하면 이를 구현할 수 있다.
kafkaListenerContainerFactory.getContainerProperties().setConsumerRebalanceListener(
new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 파티션이 해제될 때 로직
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 파티션이 할당될 때 로직
}
}
);
위 오버라이드를 사용해 특정 컨슈머에 파티션이 할당/해제 될 때마다 레디스에 실시간 컨슈머와 파티션 관계를 저장하면 된다.
카프카의 핵심 개념중 하나는 한 개의 파티션은 반드시 한 개의 컨슈머에만 할당된다는 것이다. 이를 이용해 저장해보자.
일단 우리는 하나의 서버에 여러 컨슈머를 사용하고 있으니 멀티 서버 환경에서 컨슈머의 고유값은 인스턴스 고유 값 + 컨슈머 쓰레드의 고유값이 될 것이다.
서버 운영방식에 따라 다르긴 한데 호스트에 서버를 하나만 띄우고 ASG 방식을 사용하면 인스턴스 고유값은 호스트 이름을 사용 하면 된다. 만약 도커 이미지를 사용한다든지, 하나의 호스트에 여러대의 프로세스를 띄우는 방식을 사용한다면 호스트네임과 다른 고유 값을 섞어야 한다.
우리는 서버가 최초로 실행 될 때 UUID와 같은 난수 값을 넣어 호스트네임을 설정했다.
컨슈머 쓰레드의 고유값은 인스턴스 내에서만 구별되면 되므로 아무거나 사용해도 된다. 쓰레드 ID, 쓰레드 Name 등 사용할 건 많다. 하나의 컨슈머 쓰레드에 바인딩된 리스너는 다른 쓰레드로 이동하거나 없어지지 않기 때문에 괜찮다.
https://docs.spring.io/spring-kafka/reference/kafka/thread-safety.html
Thread Safety :: Spring Kafka
Because of certain limitations in the underlying library classes still using synchronized blocks for thread coordination, applications need to be cautious when using virtual threads with concurrent message listener containers. When virtual threads are enab
docs.spring.io
따라서 레디스에는 토픽/파티션 정보를 key로 서버 프로세스 고유 값 + 프로세스 내 컨슈머 쓰레드 고유값을 value로 저장하면 된다.
개발할 때는 할당과 해제 모두 로직을 넣었는데, 정합성이 잘 안맞아서 할당(onPartitionAssigned)에만 로직을 사용했다.
찾아보니 파티션 해제는 처리중인 메시지를 모두 커밋한 이후에 시도 하는데, 메시지를 처리하기 전 지연이 발생하고 이 상태에서 리밸런싱이 발생해 다른 컨슈머에 파티션이 할당되고 기존 컨슈머 쓰레드에서는 아직 처리가 안되어 해제를 시도하지 않기 때문인 것 같다.
할당에만 로직을 넣었더니 리밸런싱 상황에서 정확히 동작하는 점을 확인했다.
개발적인 욕심 때문에 이러한 깐깐한 필터 로직을 넣긴 했는데 사실 서비스 로직에서 메시지가 중복처리 되어도 상관은 없어서 만약 이로 인해 메시지 처리가 누락되는 점이 발견되면 지우거나 다른 방식을 고민해야 할 것 같다.
독립적인 컨슈머 그룹
컨슈머 그룹 설정때문에 문제가 발생했었다.
서버에서 설정한 토픽이 아닌 다른 토픽의 파티션을 구독하려다가 에러가 발생했다.
당연히 다른 토픽에 대한 구독 key를 가지고 있지 않으니 권한오류였다.
org.apache.kafka.common.errors.TopicAuthorizationException: Not authorized to access topics: [other_topic]
참으로 이상했다. 분명 서버에서 설정하지 않은 토픽인데 도대체 이걸 왜 연결하려고 할까..
먼저 이 문제가 발생한 배경을 알아야 하는데, 여러 상황이 한번에 딱 맞아 떨어져 억까를 당했다.
- 우리는 총 3개의 환경을 사용한다 (개발, 테스트, 라이브)
- Kafka 서버는 커스텀하게 한번 감싼 사내 서비스를 사용한다 (전사 공통)
- 즉, 테스트와 라이브 환경에서 사용하는 카프카의 서버는 같다. (각 서비스는 토픽만 구분해 사용)
- 테스트, 라이브 환경의 컨슘 그룹이 하필 같다. (굳이 똑같이 맞춘것도 아니고, 꼭 달라야 한다고 생각하지도 않았다)
카프카 구조 이해에 대한 좋은 그림이 있어 가져왔다.

카프카 브로커가 컨슈머 그룹 - 컨슈머 - 토픽 관계를 메타데이터를 가지고 있다.
이게 왜 중요하냐면, 컨슘 그룹 내 컨슈머는 서버에서 설정한 값과 다르게 동작할 수 있음을 무시할 수 없기 때문이다. (컨슈머는 서버에 종속된게 아니기 때문)
아무래도 Spring에서 제공해주는 라이브러리를 사용하다보니 당연히 컨슈머는 서버내에 있고, 서버에서 설정하지 않은 토픽을 구독할 수 없다고 생각했다. 이래서 실제 내부에서 어떻게 동작하는지 정확히 이해하고 라이브러리를 쓰는 습관을 가져야 하는데 참 쉽지 않다.

설정 초기에는 이슈가 없다. 위 그림처럼 제대로 동작한다.
그러나 여기서 컨슈머 그룹내 컨슈머들이 리밸런싱 되면 문제가 발생한다.
위에서 말했듯이 초기에 서버 설정대로 토픽을 구독하는 컨슈머를 할당 받았더라도, 해당 컨슈머 그룹 내에서 리밸런싱이 발생하면 이게 다 무용지물이 되어버린다.

때문에 빨간 컨슈머를 통해 구독을 요청할 때 서버에서 설정하지 않은 토픽이기 때문에 오류가 발생했다.
만약 다른 토픽을 사용하더라도 사용하는 카프카 서버가 하나라면 컨슘그룹을 다르게 지정하자.
리스너에 점검을 걸어보자
위에서도 언급했듯이 메시지 처리에는 사내 타 서비스에 의존성이 존재한다.
때문에 긴급하게 서버 다운 없이 스트림 구독을 잠시 중단해야할 경우가 있어 이를 구현해야 했다.
크게 두가지 선택지가 있었다.
1. 메시지를 커밋하지 않고 모두 넘긴 후, 재처리 하자
점검 설정을 걸면 리스너는 토픽의 메시지를 소비하지만, 처리하지 않고 커밋도 하지 않는다.
점검 해제 이후 재처리를 하기 위해선 컨슈머를 재시작 해 각 토픽에서 커밋된 가장 최근의 메시지 다음으로 오프셋을 이동하거나 (Kafka 기본 정책) 점검을 걸었을 당시의 각 토픽의 오프셋을 저장 한뒤 점검을 해제하면 강제로 컨슈머 토픽의 오프셋을 이동시키면 된다.
생각하기 쉬운 방법은 점검 이후 서버를 일괄 재시작하면 되는데, 점검 이후마다 서버 재시작이라는 마음아픈 불편한 점이 존재한다.
또한 우리는 무중단 배포 방식을 사용하는데, 재배포 당시 같은 점검 상태여도 새롭게 뜬 서버는 실 처리를 시작하고, 아직 새롭게 뜨지 못한 서버는 실 처리를 중단하고 있어야 하기 때문에 프로세스 별 내부 변수로도 따로 관리해야 하므로 매우 불편하다. 더불어 만약 원인 모를 이유로 인해 메시지를 커밋하지 않고 넘기고 있다가 해당 파티션의 이후 메시지중 하나라도 커밋이 되어버리면 오프셋을 이동하지 않는 이상 메시지 유실을 막을 수 없다.
그래서 점검 해제 이후 방식은 오프셋을 강제로 이동시키는 방식을 사용해야 한다.

위 프로세스 처럼 점검 해제 이후 메시지를 처리하든, 하지않든 점검 당시에 저장된 각 토픽의 오프셋으로 모두 일괄 이동 후 다시 처리하는 방식이다.
Spring Kafka에서 컨슈머의 오프셋 이동은 다음처럼 사용하면 된다.
consumer.seek(topicPartition, offset);
2. 컨슈머 리스너 컨테이너 일괄 중지
다른 방법으론 Spring Kafka에서 제공하는 Listener Container를 중지하는 것이다.
리스너를 관리하는 컨테이터 전체를 중지하기 때문에 프로세스 내에선 각 컨슈머별로 개별 중지할 필요가 없다.
// 중지
kafkaListenerEndpointRegistry.getListenerContainers().forEach(MessageListenerContainer::pause);
// 재개
kafkaListenerEndpointRegistry.getListenerContainers().forEach(MessageListenerContainer::resume);
현재 우리 서버에선 하나의 토픽만 컨슘하고 있기 때문에 위처럼 해도 상관 없는데, 만약 여러개의 토픽을 컨슘하고 토픽 별 컨테이너를 중지하고 싶다면 리스너에 ID를 붙이고 찾아서 중지/재개하면 된다.
언뜻 보면 첫번째 방식보다 간편해보이고 좋은데, 한가지 문제가 있다.
우리는 멀티 서버 환경을 이용하기 때문에 점검 요청이 들어오면 현재 떠있는 모든 서버 프로세스에게 전달해줄 필요가 있다. 이를 위해 어떤 구조를 사용할까 고민했는데..
짬통 = 레디스
레디스의 pub/sub 기능을 사용하면 편하게 할 수 있다.
점검 상태를 송/수신할 채널명만 대충 맞추고 손쉽게 해결한다.
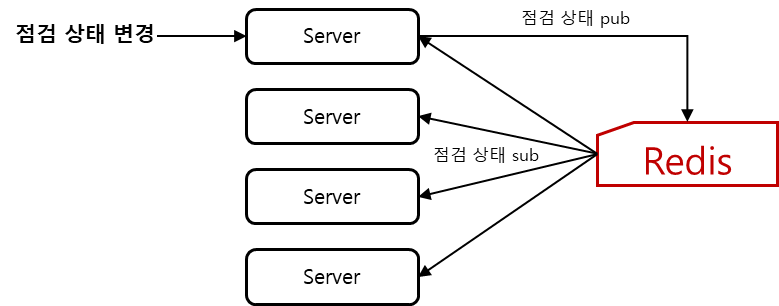
각 서버의 Listener Container가 중지/재개 요청을 제대로 받았는지 확인이 하고 싶으면 다음 값으로 알 수 있다.
public interface MessageListenerContainer extends SmartLifecycle, DisposableBean {
default boolean isPauseRequested() {
throw new UnsupportedOperationException("This container doesn't support pause/resume");
}
/**
* Return true if {@link #pause()} has been called; and all consumers in this container
* have actually paused.
* @return true if the container is paused.
* @since 2.1.5
*/
default boolean isContainerPaused() {
throw new UnsupportedOperationException("This container doesn't support pause/resume");
}
}
해당 리스너 컨테이너가 pause 요청을 받은 상태인지, 그래서 현재 어떤 상태인지를 각각 확인할 수 있는데, 리스너 컨테이너는 pause 요청을 받았을 때 즉시 중지할지, 폴링된 메시지를 우선 처리한 후 중지할지 정할 수 있기 때문이다.
kafkaListenerContainerFactory.getContainerProperties().setPauseImmediate(true);
기본 옵션은 false 인데 (라이브러리마다 다를 수 있음) 이를 true로 설정하면 컨테이너는 pause 요청을 받은 즉시 폴링한 메시지가 남아 있어도 구독을 멈춘다.
하지만 우리는 이정도까진 필요 없어서 사용하지 않았다.
또한, 컨테이너 단위가 아닌 토픽/파티션 단위로도 pause/resume을 각각 할 수 있는데, 이 역시 필요하지 않아서 사용하지 않았다. (토픽/파티션 단위의 pause 요청/현재 상태 모두 확인 가능)
public interface MessageListenerContainer extends SmartLifecycle, DisposableBean {
default void pausePartition(TopicPartition topicPartition) {
throw new UnsupportedOperationException("This container doesn't support pausing a partition");
}
/**
* Resume this partition, if paused, after the next poll(). This is a thread-safe operation, the
* actual pause is processed by the consumer thread.
* @param topicPartition the topicPartition to resume.
* @since 2.7
*/
default void resumePartition(TopicPartition topicPartition) {
throw new UnsupportedOperationException("This container doesn't support resuming a partition");
}
/**
* Whether or not this topic's partition pause has been requested.
* @param topicPartition the topic partition to check
* @return true if pause for this TopicPartition has been requested
* @since 2.7
*/
default boolean isPartitionPauseRequested(TopicPartition topicPartition) {
throw new UnsupportedOperationException("This container doesn't support pausing a partition");
}
/**
* Whether or not this topic's partition is currently paused.
* @param topicPartition the topic partition to check
* @return true if this partition has been paused.
* @since 2.7
*/
default boolean isPartitionPaused(TopicPartition topicPartition) {
throw new UnsupportedOperationException("This container doesn't support checking if a partition is paused");
}
}
추가로, 멀티 서버환경이기 때문에 현재 떠있는 모든 서버의 Listener Container 정보 (연결된 파티션, pause 요청 정보 등)를 확인하기 위해선 역시 짬통 레디스를 사용해야 한다.
모든 서버내 리스너 컨테이너가 주기적으로 자신의 정보를 레디스에 저장하는 방식 등으로 확인이 가능하다.
1,2번 모두 좋은 방식이긴 한데 파티션 리밸런싱 발생에서의 안전성, 구현 난이도 및 유지보수의 편리함을 기준으로 2번을 선택했다.
사실 둘 다 안전할 것 같긴 하다. 만약 현재 선택한 방법에서 치명적인 약점이 발견되면 1번으로 갈아탈 것이다.
결론
이렇게 대용량 스트림 데이터를 구독하는 프로세스를 설계했다.
에러 처리 / 리밸런싱 / 점검 처리가 이번 설계의 핵심이었는데 각각 현재 방식 말고 플랜 B를 가지고 있기 때문에 문제가 발생하면 언제든 갈아탈 준비가 되어있다.
SQS / RabbitMQ 같이 큐잉 방식과는 다르게 스트림 처리는 조금 복잡하고 커스텀하게 설정할 수 있는 값이 너무 많다. 대신 그만큼 더 다양한 방식의 구독처리가 가능한 게 Kafka의 장점인 것 같다.
라이브 서버를 운영하며 혹시 틀린 개념과 설계가 발견될 경우 수정하며 글을 업뎃해야겠다.
'내가 잊어버리기 싫어서 적는 개발 지식' 카테고리의 다른 글
| [Spring + SDK] 스프링 환경에서 SDK Bean을 관리하기 위한 방법 (1) | 2025.03.04 |
|---|---|
| [Spring AOP] Custom AOP와 @Transactional Order에 관하여 (0) | 2024.12.24 |
| [Spring Batch] Job Instance 추가시, 데드락 문제 해결 (7) | 2024.05.24 |
| [MySQL] DB 재시작과 auto_increment의 관계성 (0) | 2024.01.30 |
| [Spring JPA] 한 트랜잭션 내부에서의 외부 API 콜과 엮인 영속성 문제 (3) | 2024.01.12 |



