우리 팀은 수 많은 데이터베이스 서비스중 MySQL을 사용한다.
현재 개발하고 있는 서비스에서 사용하고 있는 DB는 꽤 오래전에 구축되었는데, MySQL 5.7 버전을 사용한다.
개발하면서 MySQL 5.7 버전에서는 쓸 수 없는 기능들로 많이 고생했기 때문에 최근 8.0 버전으로 업그레이드를 진행했다.
개발대역에서 자체적으로 5.7에서 8버전으로의 업그레이드를 진행했었는데, 서비스 상의 큰 이슈도 없었고 업그레이드 하는 시간도 많은 시간을 요구하지 않았기에 QA 대역에서 그대로 진행했다.
그런데 문제가 생겼다.
AUTO_INCREMENT 의 COUNTER
AUTO_INCREMENT(이하 AI)는 테이블의 pk 컬럼에 적용했을 때 꽤 편리한 속성이다.
데이터베이스 엔진이 자체적으로 PK를 카운팅하며 insert시 적용해주기 때문에 개발자는 PK를 직접 구하거나 신경 쓸 필요가 없다고 생각했다.
문제는 원본과 백업을 동시에 관리하는 테이블에서 발생했다.
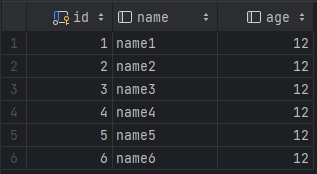
위와 같은 상태에서 아래 3 rows를 지워보겠다.

이때, pk를 지정하지 않고 새로운 row를 삽입하면 새로 삽입된 row의 pk는 몇이 될까?
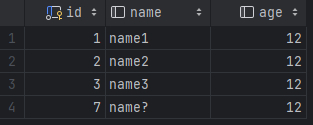
이전에 삭제했던 row들 까지 고려하여 새로운 row의 id는 7이 되었다.
우리는 특정 테이블에서 데이터가 더 이상 필요하지 않게 되면 쿼리 부하를 줄이기 위해 테이블에서 해당 내용을 삭제 한 후, 백업 테이블에 보관한다.
이때, 삭제되었던 row까지 고려해 새로 생기는 row의 pk를 제어하기 때문에 큰 이슈가 없을 것 같았는데, 최근 DB를 업그레이드 하며 문제점이 생겼다.
이미지 (2) 번의 상태에서 DB 업그레이드를 위해 재시작을 했더니 AI의 counter가 현재 테이블에 존재하는 pk의 max 값 + 1을 가리켰다.
즉, 이 상태에서 row를 새로 추가했더니 id를 4로 가지는 row가 추가되었다.
우리는 원본과 백업을 union 했을 때, id는 항상 unique한 속성을 유지해야 정상적인 서비스 운영이 가능하도록 설계가 되어있었는데, 백업과 중복된 pk가 생기다보니 생각하지 못한 오류가 이곳저곳에서 발생했다.
공식문서를 찾아보니, MySQL 8.0 미만의 버전에서는 AI의 counter를 DB 인스턴스의 디스크가 아닌 메모리에 저장하기 때문에 DB가 재시작 되면 이를 초기화 한다고 한다.
MySQL :: MySQL 5.7 Reference Manual :: 14.6.1.6 AUTO_INCREMENT Handling in InnoDB
14.6.1.6 AUTO_INCREMENT Handling in InnoDB InnoDB provides a configurable locking mechanism that can significantly improve scalability and performance of SQL statements that add rows to tables with AUTO_INCREMENT columns. To use the AUTO_INCREMENT mechani
dev.mysql.com
이때, 초기화 하는 값은 현재 테이블의 max(pk) + 1 이라, 위 문제가 발생했다.
다행히, 8.0 이상의 버전부터는 이 문제점이 개선되었다고 한다.
원인 파악과 해결
위 문제가 다행히 QA환경에서 발견되어 참 다행이라고 생각한다.
그렇다면 LIVE 환경에서는 이를 어떻게 대처해야할까?
LIVE환경도 QA와 같이 MySQL 5.7 버전을 사용하기 때문에 분명 같은 문제가 발생할 것이다.
문제를 해결하려면 DB가 초기화 하는 AI의 counter 값이 max(pk) + 1 니까, 이를 실제로 유효한 값으로 유지하면 된다.
따라서 DB 업그레이드 직전, 더 이상의 DB insert 작업이 없도록 점검 등을 설정한 후, 개발자가 수동으로 해당 문제가 발생할 수 있는 원본 테이블들에 row를 임의로 적재한다.
이후, 이 row가 삭제되어 백업테이블로 가지 않는다는 것만 보장이 된다면 DB가 재시작되어 현재 테이블의 max(pk) + 1로 AI의 counter를 초기화 했을 때, 문제가 발생하지 않을 것이다.
최신 버전을 쓰는건 다 이유가 있다.
'내가 잊어버리기 싫어서 적는 개발 지식' 카테고리의 다른 글
| [Spring + SDK] 스프링 환경에서 SDK Bean을 관리하기 위한 방법 (1) | 2025.03.04 |
|---|---|
| [Spring AOP] Custom AOP와 @Transactional Order에 관하여 (0) | 2024.12.24 |
| [Spring + Kafka] 대용량 스트림 메시지 구독 설계 (1) | 2024.11.01 |
| [Spring Batch] Job Instance 추가시, 데드락 문제 해결 (7) | 2024.05.24 |
| [Spring JPA] 한 트랜잭션 내부에서의 외부 API 콜과 엮인 영속성 문제 (3) | 2024.01.12 |



