* 이 글에 관련된 모든 내용은 Computer Networking A Top-Down Approach 7th에서 가져온 내용이다. *
이번 챕터에서는 데이터링크 레이어에 대해서 알아보겠다.
Data Link Layer
데이터 링크 레이어는 라우터간의 링크에서 작동한다.
링크들에는 여러 종류가 있다.(유선, 무선, LAN..)
이 레이어에서의 데이터는 frame단위로 부른다.
때문에 데이터 링크 레이어의 궁극적인 목표는 링크로 연결된 노드와 노드간의 프레임전달이라고 볼 수 있다.
앞서 MAC주소와 그 필요성에 대해 알아보았다.
데이터 링크 레이어에서는 이 MAC주소가 중요하다. 메시지를 실제로 어떤 host에게 보낼지 정해야 하기 때문인데, 그래서 frame의 헤더부분에 MAC주소를 넣어 보낸다. 이는 나중에 더 자세히 설명하겠다.
또한 데이터 링크 레이어에서는 에러에 대한 detection과 recovery를 지원한다.
Error detection에는 parity bit이나 CRC가 사용되고, recovery에는 FEC나 ARQ가 사용된다.
이 레이어에서는 상위레이어(네트워크 레이어)에서 온 datagram의 앞부분에 header와 뒷부분에 trailer를 붙여서 frame으로 만드는데, 이때 trailer부분에 CRC가 포함되어 있다.
Error를 recovery하는 방식에는 두가지가 있다.
1. link by link간의 recovery
2. end-to-end간의 recovery
loss가 많은 wireless에서는 당연 link-by-link 방식을 써야 한다. 그러나 그렇지 않은 환경(유선)에서는 loss가 매우 드물게 일어나기 때문에 link-by-link간의 recovery방식은 오히려 독이될 수 있다. 때문에 이럴 때는 end-to-end간의 recovery방식을 채택하기도 한다.
실제로 기술의 발전으로 인해 요즘은 loss가 발생하는 일이 매우 적어서 end-to-end recovery방식을 선호하다고 한다.
마지막으로 이 레이어에선 Flowe control과 half-duplex, full-duplex방식을 모두 지원한다.
(half-duplex는 양방향으로 통신이 가능하지만 동시에는 안됨)
MAC(Medium Access Control)

MAC은 브로드캐스트 네트워크에서 작동한다.
point-to-point방식과는 달리 브로드캐스트 네트워크 에서는 여러 곳에서 동시에 접근(메시지를 보냄)할 수 있기 때문에 그에 대한 구별이 필요하다. 이를 위해 MAC이 필요하다.
Framing
다른 노드에서 전달받은 frame을 순서에 맞게 잘라야 처리가 가능할 것이다. (어디까지가 하나의 frame인지 구별)
때문에 어디가 시작이고 어디가 마지막인지 구별하는 자체 프로토콜이 필요하다.
컴퓨터의 메시지를 0과 1로만 나타나기 때문에 특정한 패턴을 두어 frame의 시작과 마지막을 구별한다.
이를 위해선 많은 방법이 있지만 요즘은 Bit-stuffing방식과 Octet-struffing방식을 사용한다.
1. Bit-Stuffing
frame의 앞 뒤에 적절한 Flag를 넣어 보내고 받는 방식이다. 이때 flag는 01111110 (1이 6개)이다.

이렇게 앞뒤에 01111110을 넣어 해당 패턴이 보이면 자르는 방식이다.
그러나 만약 frame의 일부에 01111110이라는 데이터가 존재하게 되면 리시버는 이를 끝 flag로 인식하고 끊어버릴 것이다. 때문에 sender는 1이 연속해서 5개가 나오면 무조건 0을 추가하여 보낸다. 또한 리시버는 1이 연속해서 5개가 나오면 무조건 뒤에 0을 하나 제거한다.
예를 살펴보자
sender가 보낼 frame이 011111010이다.
만약 sender가 이를 그대로 보내버리면 리시버는 1이 5개가 연속이 나온 후 0을 제거하므로 01111110을 받을 것이다.
때문에 011111010을 보낼 때는 1이 연속된 5개 이후에 0을 추가하여 0111110010으로 보낸다.
그리고 리시버는 1이 다섯개 나온 후의 0을 제거하여 011111010를 온전히 받는다.
추가로 이 기능은 SW에서 개발자가 구현하는 것이 아니라 이를 지원하는 HW chip이 따로 있다. 8bit단위에 0을 추가하는 작업이다 보니 SW에서 구현하기는 어렵다고 볼 수 있다.
2. Octet-Stuffing
위의 방식도 큰 문제는 없지만 8bit단위로 처리하는 SW에서 중간에 1bit를 추가해 보내기는 어렵다. (때문에 HW에서 기능을 지원했음)
이 불편함을 해소하기 위해 flag는 똑같이 하지만 1bit를 추가하는 것이 아닌 8bit를 추가하자는 아이디어가 이 방식이다.

Flag는 01111110 = 0x7E로 위 방식과 똑같다.
그렇다면 Frame에서 0x7E가 나온다면 어떻게 처리할까?
Control escape octet을 추가한다. (0x7d = 01111101)
sender는 자신이 보낼 frame에 flag와 같은 0x7E가 보인다면 그 앞에 탈출 옥텟 0x7d을 추가한다. 그리고 0x7E였던 부분을 0x5E로 바꾼다. (0x5E에 exclusive or 0x20을 하면 0x7E가 됨)
즉, 결과적으로 자신이 보낼 frame에 0x7E가 보이면 0x7D 0x5E를 붙여 보내는 것이다.
리시버는 해당 탈출 옥텟 0x7D를 보면 그건 무시하고 그 다음 옥텟 0x5E에 다시 exclusive or 0x20을 해 원래 데이터인 0x7E로 복원한다.
그렇다면 또 의문이 생긴다.
센더가 보낼 Frame에 탈출 옥텟 0x7D가 있다면?
만약 아무런 처리를 하지 않고 보내면 리시버는 0x7D를 본 이후 해당 옥텟을 탈출 옥텟으로 인지한 후, 다음 옥텟에 exclusive or 0x20을 하여 처리할 것이다. 때문에 센더는 자신이 보낼 Frame에 탈출 옥텟 0x7D가 있다면 0x7D 이후에 0x7D에 exclusive or 0x20을 한 0x5D를 보낸다.
예를 들어 리시버가 보낼 데이터가 0x7D 0x30이라면 탈출 옥텟이 보이기 때문에 0x7D 0x5D 0x30을 보내는 것이다.
이를 받은 리시버는 탈출 옥텟 0x7D가 보이기 때문에 해당 옥텟을 무시하고 그 다음 옥텟에 exclusive or 0x20을 하여 처리한다. 즉, 0x5D exclusive or 0x20 인 0x7D와 0x30을 제대로 받을 수 있는 것이다.
Error Handling
Reliable한 전송을 하기 위해 data link layer에서는 두가지 방법을 제안한다.
1. FEC(Forward Error Correctino)
- Redundant bit를 붙여보내 리시버가 에러를 체크할 수 있게끔 하는 것이다. 여기서 Redundant bit란 보낼 데이터와 관련이 있는 비트를 추가로 보내는 것이다. 그냥 플래그정도라고 생각하면 편하다.
2. Retransmission
- 에러를 detection한 리시버는 재전송을 요구할 수 있다. 이때 ARQ매커니즘이 사용되는데 이는 여기(링크)에서 자세히 다루었다. (Go Back N, Selective Repeat, Stop and wait)
Error Cotnrol
Erorr control에는 위에서 말한것 처럼 redundancy를 가진 어떤 데이터를 추가해 보내는 것이다.

위와 같이 데이터 D에 관련성을 가진 EDC를 붙여 보내면 리시버는 해당 D와 EDC의 이해관계를 파악한 후에 에러가 났는지 아닌지 판단한다.

데이터와 EDC의 경우의 수를 나타내보면 위와 같다.
m bit의 데이터에 r bit의 EDC를 붙여 데이터를 전송한다고 가정해보자. 이때 전체 코드의 길이는 n bit가 될 것이다.
데이터가 전송되면서 어떤 에러로 인해 데이터에 변형이 일어나게 되면 A로 출발했던 점이 B로 가게 되는 경우가 발생한다. (초록색 밖) 이럴때는 전달받은 데이터가 legal한 범위를 벗어낫기 때문에 바로 에러를 detection할 수 있다.
그러나 만약 A가 에러로 인해 변질되었는데 C로 가게 된다면 어떡할까? 리시버는 이게 원래부터 C였는지 A가 C로 변했는지 알 수가 없다. (legal한 범위 내에 들어왔기 때문)
위와 같은 현상때문에 error detection과 correction은 100%의 신뢰성을 보장해주지 않는다.
Hamming distance
에러 컨트롤에는 Hamming distance(해밍거리)를 사용한다.
해밍거리는 leagl한 범위내에서 어떤 두 pair간에 차이가나는 bit중 최소값을 의미한다.
예를 들어 위 그림에서 초록색 범위내에
1번 1000
2번 1011
3번 0101
이 있다고 가정해보자.
1번과 2번의 차이가나는 bit수는 2, 1번과 3번은 3, 2번과 3번은 3이므로 위에서의 해밍거리는 2라고 볼 수 있다.
모든 legal한 범위내에 있는 코드들이 서로 해밍거리 이상의 bit수만큼 차이가 나기 때문에 해밍거리 미만의 bit수에 대해선 error detection이 가능하다.
즉 해밍거리가 d+1이면 d만큼의 bit에 대해 error detection이 가능하다.
예를들어 leagl한 범위내에 111 000 두개가 존재한다고 가정해보자.
이때 해밍거리는 3이고 010이라는 데이터가 들어왔다면 000과 비교했을 때 차이나는 bit수는 2이다.
해밍거리가 3이므로 legal한 범위내에 존재하는 모든 bit의 차이는 최소 3bit이상씩 이기 때문에 010언 legal한 범위내에 없다는 판단을 내릴 수 있다.
또한 해밍거리가 2d+1이라면 d bit만큼은 error corection이 가능하다. 위의 상황에서 d는 1이므로 010은 000으로 고쳐질 수 있는 것이다.
Parity Check Code
parity bit는 데이터 뒤에 1또는 0을 붙여 전체 1의 개수가 even또는 odd가 되도록 만드는 것이다. (even일때는 even parity check, odd일땐 odd parity check)
even parity check일때 예를 들어보면 다음과 같다.
1001이라는 데이터가 있어서 전체 1의 개수가 짝수가 되도록 뒤에 0을 붙여 보낸다.
이때 에러로 인해 1001이 1110이 되었다고 가정해보자 (3bits error)
리시버는 11100을 받을텐데 even parity check에서 전체 1의 개수가 홀수이므로 error가 났음을 인지할 수 있다.
그러나 1001이 1100이 되었다고 가정해보자. (2bits error)
리시버는 11000을 받을 텐데 전체 1의 개수가 짝수이므로 에러를 인지할 수 없다.
위의 두상황의 차이가 보이는가? 바로 에러의 bits수가 짝수와 홀수일때가 다르다.
기본적으로 parity check code는 error bit가 홀수개 일때만 에러를 감지할 수 있다. 때문에 1, 3, 5, 7 ....만큼의 비트수에 대해 에러를 detection할 수 있다.
일반화하면 1bit수에 대해 에러감지가 가능하다고 볼 수 있다. (2가 안되기 때문에 뒤에거는 X)
해밍거리 부분에서 해밍거리가 d+1일때 d만큼의 bit수에 대해 에러감지가 가능한걸 증명했으므로 parity check code에서의 해밍거리는 2라고 볼 수 있다.
Parity Checking
위의 방식에서는 parity bit을 1차원으로 인지하여 계산했다.
이를 single bit parity라고 한다.

이때 해밍거리는 2라고 위에서 말했다.
그렇다면 해밍거리를 늘리기 위해선 어떻게 해야할까?
2차원으로 생각하면 된다.
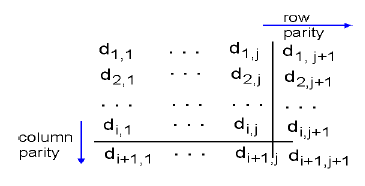
parity bit를 위와같이 2차원으로 표현하여 에러체킹을 한다.
예를 들어보자.
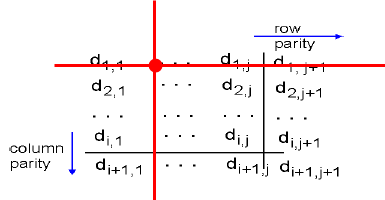
만약 위와 같이 한곳에서만 에러가 나면 row쪽에서도 에러 탐지가 가능하고 cloumn쪽에서도 에러 탐지가 가능하다. (둘다 1로 홀수이기 때문, parity bit에서는 홀수 bit가 에러날때만 탐지 가능)
2개일때는 어떨까?

극단적으로 나란히 두 곳에서 에러가 발생하게 되면 columns쪽에서는 에러탐지가 불가능(짝수개이기 때문)하지만 row쪽에서 가능하다.
3개일때는 어떨까?

X친 부분에서는 에러가 짝수개 이므로 탐지가 불가능하지만 O를 친 부분에서는 1개이므로 탐지가 가능하다.
4개일때는?

위 그림과 같이 모든 부분에서 에러가 짝수개이기 때문에 에러탐지가 불가능하다.
즉 2차원 parity check에서는 error가 3개까지 났을 때 detection이 가능하므로 해밍거리가 4라고 볼 수 있다.
Internet Checksum
TCP나 UDP에 사용하는 checksum방식과 동일하다.
모든 bit를 다 훑기때문에 성능은 좋지 못하지만 구현이 단순하고 쉽다.
CRC(Cyclic Redundacny Check)
데이터 링크 레이어에서 가장 많이 사용하는 방법이다.
주로 하드웨어에서 생성되고 에러를 체크한다.
성능이 매우 좋고 간단하여 많이 사용한다.
기본적인 아이디어는 data를 polynomial로 표현하는 것이다.
예를들어 101011은 다음과 같이 표현된다.

때문에 data에 CRC bit를 더한 전체 데이터 bit의 표현은 다음과 같다.

D bit뒤에 CRC bit를 더하므로 D(x)에 x^(CRC의 bit수) + R(X)라고 볼 수 있다.
그렇다면 보낼 R(x)는 어떻게 정할까?
하드웨어간 약속을한 generator (G(x))를 통해 만든다. 이때 generator또한 다항식으로 이루어져있다.
D(x) : D의 polynomial
G(x) : genrator polynomail (degree = r)
R(x)는 D(x)*x^r을 G(x)로 나눈 나머지이다.
때문에 다음과 같은 식이 성립한다.

그렇다면 왜 R(x)를 더해 보내는 것일까?
위의 식에서 Q(x)를 몫이라고 해보자.
그렇다면 다음과 같은 식이 성립한다.
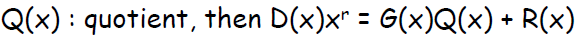
CRC genration에선 modulo-2연산을 사용한다. 모든 연산에 대해 exclusive or연산을 하는 것이다.
위의 식에서 양변에 R(x)를 더하면 다음과 같다.
R(x)+D(x)*x^r = G(x)Q(x)+R(x)+R(x)
R(x) exclusive or R(x) = 0이므로 최종적으로 다음과 같은 식이 성립한다.

즉 sender가 보내는 데이터는 G(x)Q(x)와 같은데, 이를 받은 리시버는 generator G(x)로 나눈 후, 나누어 떨어지지 않는다면 에러가 발생했다는 것을 짐작할 수 있다.
위의 과정을 예시로 살펴보자.
보낼 데이터의 메시지는 101110이고, genrator는 1001이라고 가정하자.

이때 R(x) = D(x)*x^r / G(x)를 구해보면 다음과 같다. 이때 주의할 점은 CRC Generation에서는 modulo-2연산을 사용하기 때문에 exclusive or연산을 사용해야 한다.

위와 같이 R(x) = x+1 을 구했다면 센더는 최종적으로 D(x)*x^3+R(x)를 보내면 된다.

그렇다면 이 값을 받은 리시버는 error를 어떻게 detection할까?
앞에서도 잠깐 언급했지만 리시버는 받은 데이터를 G(x)로 나누어서 나누어 떨어지지 않는다면 에러로 간주한다.
위 식은 sender가 보내는 최종 데이터이다.
위 식을 P(x)라고 하겠다.
만약 sender가 P(x)를 리시버에게 보내는데 그 와중에 에러가 생겨 리시버가 받는 데이터가 P(x)+E(x)라고 생각해보자.
(여기서는 modulo-2연산을 사용하기 때문에 10101을 보냈는데 만약 10010이 도착했다면 E(x) = 00111이 될것이다.
(바뀐 부분만 1)
때문에 리시버 입장에서 받은 데이터를 G(x)로 나누게 되면 E(x)가 남아버리게 되는 것이다.
그리고 리시버는 에러가 났음을 인지할 수 있다.
그렇다면 E(x)조차 G(x)로 나누어 떨어져버리면 어떡할까?
어쩔 수 없다. 때문에 에러 체킹은 절대 완벽할 수 없다고 한 것이다.
CRC는 다음과 같은 상황에 대해 에러체킹이 가능하다고 알려져있다.
error난 비트수가 홀수 일때 => 모두 에러 체킹이 가능
burst error (연속된 에러)가 r bit 보다 작을 때, 모두 에러 체킹이 가능 (G(x)로 나누어도 0이 될수가 없기 때문)
most 2-bit에 대한 에러 (항상은 아님)
most burst error가 r bit보다 클 때 (항상은 아님)
많은 수학자들이 연구한 끝에 다음 bit수에 대해서는 generator를 다음과 같이 쓰는게 좋다고 정했다.

세상에 완벽한건 없는 것 같다.
'컴퓨터 네트워크 > Computer Networking 정리' 카테고리의 다른 글
| CH6 : Data Link Layer (3) (0) | 2021.12.08 |
|---|---|
| CH6 : Data Link Layer (2) (0) | 2021.12.02 |
| 패킷 전송(Packet Delivery)_ARP (0) | 2021.11.25 |
| CH5 : Network Layer Control Plane (2) (0) | 2021.11.19 |
| CH5 : Network Layer Control Plane (1) (0) | 2021.11.17 |



