* 이 글에 관련된 모든 내용은 Computer Networking A Top-Down Approach 7th에서 가져온 내용이다. *
Routing
목적지까지 데이터를 보낼 때 어떤 경로를 거쳐 보내야 할지 정하는 것은 매우 중요하다.
실제로 src에서 dst까지 다양한 경로가 존재할 수 있기 때문에 최적의 path를 찾기 위한 방법을 제시해주는 것이 Routing Algorithm이다.
이때 라우터와 그 간의 링크들은 그래프에서 vertex와 edge로 표현될 수 있다.

이렇게 각 링크의 트래픽양이 다르고 어떤 경로를 통해 데이터를 보냈을 때 가장 적은 트래픽의 영향을 받으며 보낼 수 있을까?
알고리즘 파트에서 배웠던 그래프에서의 최단거리 알고리즘들이 떠오른다. (벨만포드, 다익스트라, 플로이드...)
Routing Algorithm
라우팅 알고리즘의 필요성을 알았다,
그렇다면 라우팅 알고리즘에는 어떤 종류가 있을까?
일단 라우팅의 종류에 대해 알아보아야 한다.
1. Static Routing
어떤 네트워크에서 링크들의 트래픽을 고려하지 않고 정적으로 path를 할당하는 방식이다.
일단 구현이 단순하고 생각하기도 쉽지만 한 링크에 대해 트래픽이 몰리거나 해당 path에서 어떤 링크가 고장이 나면 데이터를 보내기가 힘들다.
때문에 path가 하나밖에 존재하지 않는 경우에 사용되고, 실제로는 잘 사용되지 않는다. (Dynamic routing에 별첨스프를 더하듯이 사용된다)
2. Dynamic Routing
일단 링크의 트래픽에 영향을 받는다.
때문에 어떤 path를 선택할지가 현재 네트워크 상황에 따라 달라진다.
그러나 항상 최적의 path를 찾기 때문에 잘못하면 oscillation이 생길 수 있다.
* Ocillation
Ocillation은 path가 이리변했다 휙 저리변했다 하는 것이다.

현재 목적지는 A이다.
1번 : D->A, C->B, B->A로 갈때 현재 트래픽이 다음과 같다.
2번 : D입장에서는 시계방향으로 도는 것이 이득이고, C도 그렇고 B도 그렇다. 때문에 시계방향으로 가중치들이 더해진다.
3번 : 2번에서와 마찬가지로 D,C,B의 입장에서는 이제 반시계방향으로 가는 것이 이득이다. 때문에 반대로 가중치가 더해진다.
4번 : 또 다시 모든 라우터에서 시계방향으로 가는 것이 이득이므로 또또 다시 반대로 가중치가 더해진다.
이렇게 path가 이리 갔다가 다시 휙 저리갔다가 바뀌게 되면 로스가 발생할 수 있다. (no-stable)
Global vs Decentralized Informatino
Global
모든 라우터가 complete한 topology를 가지고 있다. (link cost)
Link State 알고리즘이다.
Decentralized
라우터는 물리적으로 연결된 이웃들만 알고 있다. (link cost)
Global과 달리 부분적인 정보들만 알고있다고 보면 된다.
Distance Vector 알고리즘이다.
이제 Link state방식과 Distance vector방식에 대해 알아보자.
Link-State Routing Algorithm
이 방식에서는 다익스트라 알고리즘을 사용한다.
그런데 뭔가 모순이 있다. 현재 시작지점에서 우리는 네트워크의 상황에 대해 아무것도 모른다.
그러나 어떤 시작점에서 다익스트라 알고리즘을 통해 최소 경로를 알고싶다면 해당 네트워크의 모든 정보를 알아야 할것이다.
아니 아무것도 모르니까 다익스트라 알고리즘을 통해서 최소경로를 찾고싶은건데, 모든 네트워크에 속해있는 링크의 cost정보를 알아야 한다니? 약간 모순같다.
때문에 flooding방식을 사용한다. 현재 시작지점에서 나는 모든 라우터의 정보를 알아야 하기 때문에 LSP(Link State Packet)을 만들어 존재하는 모든 라우터에게 flooding(브로드캐스트 방식)을 통해 각 라우터의 정보를 알아온다.
그 후에 다익스트라 알고리즘을 통해 최적의 경로를 계산한다.
다익스트라 알고리즘의 과정에 대해선 여기(링크)에 자세히 설명되어 있으니 이해하고 오자.
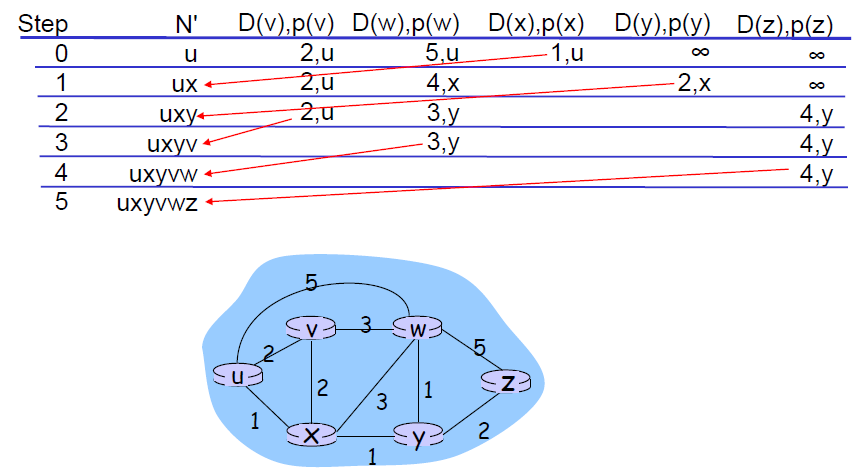
다익스트라 알고리즘 과정을 마친후의 모습이다. 이때 N은 P로도 불리는데 지금까지 방문을 완료한 라우터를 set으로 표현한 것이다.
최단거리의 path를 자명하게 알 수 있지만 LSP를 통해 모든 라우터의 정보를 가져와야 한다는 점이 단점이다. (매우 많은 트래픽이 예상)
때문에 LSP의 과정에서 최소한으로 탐색하기 위해 이미 방문했던 vertex를 방문하지 않도록 하는데 이때 sequence number와 TTL이 사용된다.
Distance Vector Routing Algorithm
이 알고리즘을 그래프에서으 최단거리를 찾기위한 벨만-포드 알고리즘을 이용한다.
보통 프로그래밍 문제를 풀때 그래프에서 최단거리를 찾으려면 다익스트라(한지점) 또는 플로이드(모든 지점)를 이용하고 벨만포드는 잘 이용하지 않는다.
왜냐하면 프로그래밍 문제를 풀때는 그래프의 모든 노드, 엣지의 정보를 알고 시작하고, 모든 정보를 안다고 가정했을 때는 벨만포드보다는 다익스트라또는 플로이드가 구현도 쉽고 빠르기 때문이다.
그러나 실제 네트워크 상황은 좀 다르다.
위에서 링크스테이트 알고리즘을 설명할 때 한 라우터는 네트워크상의 모든 라우터의 정보를 알고 있어야 했다. 이 말은 어떤 라우터는 자신의 정보를 이웃의 이웃, 또 그 이웃의 이웃에게 모두 줘야한다는 소리이다.
벨만-포드 알고리즘은 그러지 않아도 된다.
자신의 정보를 자신에게 이웃한 노드에게만 전달하면 된다. 이때 전달하는 정보는 방향성과 그 크기이다.
그래서 Distance vector라는 이름이 붙는다.
벨만-포드의 알고리즘 설명은 이 블로그에 없으므로 과정을 살펴보자.

이 알고리즘에서 중요한 포인트는 어떤 노드는 자신이 알고있는 정보(방향성과 크기)를 주기적으로 자신의 이웃에게 전달해주는 것이다.
한 과정에서의 예시를 살펴보자.

Du(Z)는 현재까지 찾은 u에서 z까지 갈때의 최소 거리이다.
c(u,v)는 u부터 v까지의 코스트이다.
현재 u는 v,x,w와 연결이 되어있고 이때 발생할 수 있는 최소 cost는 다음과 같다.

천천히 한번 따라가보자.
위의 과정을 도착지부터 src까지 순서대로 모든노드에서 진행하면 된다.

모든 과정을 살펴보자. 벨만 포드는 destination부터 시작한다.
목적지에서 자신에게 올 수 있는 정보를 자신의 이웃들에게 업데이트 해준다.
또한 어떤 노드가 목적지로 갈 수 있는 최소 거리를 알았으면 그 방향성과 가중치를 자신에게 이웃한 노드에게 전달해준다. (빨간 글씨)
맨위에 현재 4가된 노드만을 설명하자면 원래는 5였는데 오른쪽 가중치가 2인 노드에서 정보가 왔을때 그 노드로 가는 가중치(2) + 현재 그 노드의 d(2)가 현재 자신의 노드 d(5)보다 작으므로 업데이트 시킨것이다.
결국 다음과 같아진다.

이 과정을 계속 반복하다 보면 답을 얻을 수 있다.
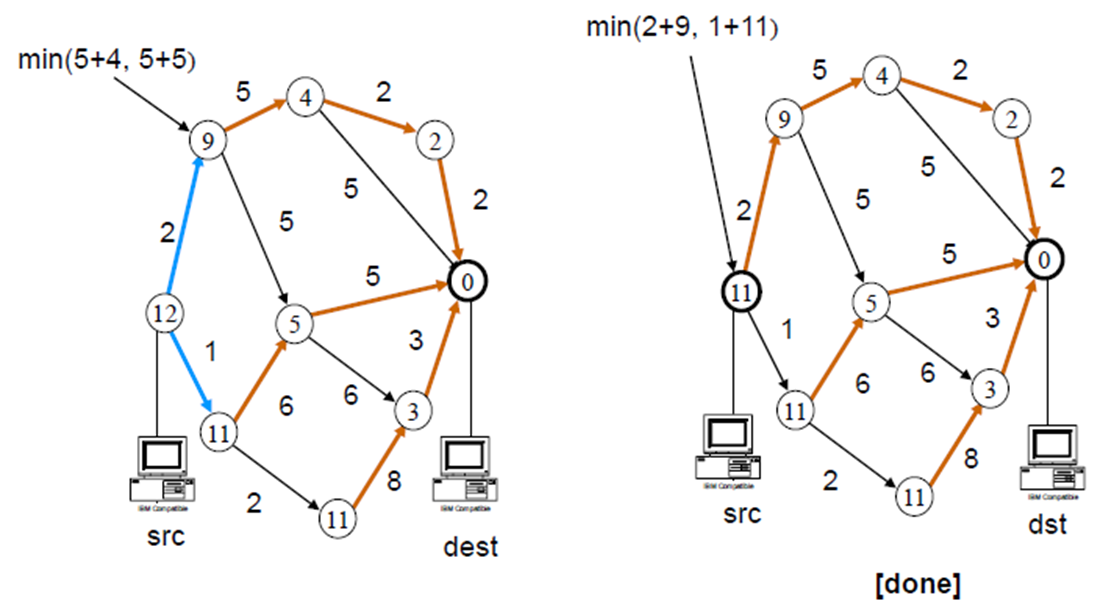
모든 노드들에게 정보를 알리기 위해 flooding하는 과정이 없고 답도 간단한 방법을 통해 알 수 있지만 문제점이 있다.
Count-to-Infinity
선형의 네트워크가 존재한다고 가정해보자.

벨만-포드 알고리즘을 통해 A부터 차례대로 나아가면 다음과 같이 구해진다. (노드간의 거리는 1)
예를들어 A로부터 1이라는 정보를 전달받은 B는 그 정보를 다시 A와 C에게 뿌린다.
이때 A->B->A로 가는 cost는 2일테니 이미 0이 채워진 A로써는 업데이트할 필요가 없다.
A->B->C로 가는 cost는 2가 될테니 현재 무한대보다는 작으므로 업데이트 한다.
위와 같이 모두 연결이 되어있는 상태에서 주기적으로 자신의 정보를 이웃노드들에게 전파한다.
예를 들어,
A는 B에게 자신을 통해 (0) B로 갈 수 있는 (1) cost인 1을 보내주고
C는 B에게 자신을 통해 (2) B로 갈 수 있는 (1) cost인 3을 보내준다.
더 작은 값을 업데이트 하므로 B는 계속 1이라는 D를 유지할 수 있다.
그러나 만약 이 상황에서 A와 B의 커넥션이 끊어진다면?
이때 발생하는 문제가 count-to-infinity이다. 커넥션이 끊어졌다는 것을 알기 위해 무한대의 시간이 걸린다는 것이다.

위의 그림을 따라가보자.
After1 exchange에서의 과정을 살펴보자.
A와 B의 커넥션이 끊어졌을 때 B가 자신의 이웃에게 자신의 정보를 업데이트 하려고 한다.
A는 B에게 정보를 줄 수 없으니 그대로 있고 C는 B에게 3이라는 정보를 줄 것이다.
그렇다면 현재 자신에게 온 정보가 3밖에 없으니 3으로 업데이트 한다.
C입장에서도 살펴보자.
정보의 교환은 순차적으로 이루어지는 것이 아니라 동시에 이루어진다. (B가 C에게, C가 B에게, C가 D에게, D가 C에게...)
즉 업데이트할 때의 필요한 정보는 직전 과정에서 완료했던 정보를 가져다가 쓰는 것이다.
C는 현재 B로부터 1+1, D로부터 3+1이라는 정보가 오므로 2로 업데이트 한다.
D의 입장에서 살펴보자.
C에서 2+1, E에서 4+1이 오므로 3으로 업데이트 한다.
이 과정을 쭉쭉 따라가보면 언젠가 모두 무한대가 나올 것인데 무한대가 나와야만 A와 B의 커넥션이 끊어졌다고 알 수 있는 것이다.
이 문제를 해결하기 위해 여러 방법들이 나왔다.
한 솔루션이 아닌 여러 방법이 나왔다는 것은 한가지 솔루션만을 통해 모든 경우의 수에 대해 커버할 수 없다는 것이다.
1. Define a maximum distacne (최대를 무한대가 아닌 특정 수로 지정하는 방식)
2. Split horizon (자신을 통해 best-path가 정해졌다면 그 path에 포함된 (지나온)애들에게는 정보를 주지 않음)
3. Triggered update (노드가 자신의 이웃에게 주는 업데이트 주기를 따르지 않고 정보가 업데이트 되면 바로 보냄)
4. Path hold-down (복잡함)
5. Path-vector (path기록하여 그 노드를 통해 왔으면 정보를 안줌)
Split horizon with Poisoned reverse
split horizon방식은 자신에게 오는 best-path중 어떤 노드가 포함되어 있으면 그 노드에게 정보를 알리지 않는 것이다.
반면에 poisoned reverse는 못간다고 알려주는 것이다. (split horizon보다 적극적)
둘의 차이는 패킷로스에서 극명하게 갈린다.
이 알고리즘에선 RIP라는 프로토콜을 쓰는데 이 프로토콜은 UDP이다.
UDP는 loss에 대해 에러 리커버리를 하는 과정이 없기때문에 패킷이 도착했는지 안했는지를 알 수가 없다.
split horizon방식에서는 정보를 보내지 않기 때문에 이게 패킷이 로스가 난건지 아니면 best-path에 포함되어 보내지 않은 것인지를 구별할 수가 없다.

예를 들어 after 1에서,
B는 C로부터 3이라는 정보를 받았어야 하지만 C입장에서 자신에게 오는 best-path에는 B가 포함되어 있기 때문에 무한대를 보내준다.
B는 받은 정보가 무한대밖에 없으므로 무한대로 업데이트하는 것이다.
그러나 이 방식도 문제가 없는것은 아니다.
선형의 네트워크에서는 이 split-horizon방식이 통하지만 cycle이 있는 경우에는 그렇지 않다.

현재 목적지는 D이고 각 링크의 가중치는 1이다.
C와 D의 커넥션이 끊어지기 전 구해진 D는 1번과 같을 것이다.
C와 D의 커넥션이 끊어진 후의 과정을 살펴보자
2번 과정
C입장에서 D로부터 받는 정보는 없고, A와 B는 자신에게 오는 best-path중 C가 포함되어 있으니 무한대를 준다.
때문에 C는 무한대로 업데이트 된다. 여기까진 OK
3번 과정
A의 입장에서 C는 무한대를 주고 B는 3을 주기 때문에 3으로 업데이트 하는데 그때 자신에게 오는 best-path에는 B가 포함되어 있다고 생각한다.
B의 입장에서 C는 무한대를 주고 A는 3을 주기 때문에 3으로 업데이트 하는데 그때 자신에게 오는 best-path에는 A가 포함되어 있다고 생각한다.
4번 과정
A의 입장에서 C는 무한대를 주고 B는 자신에게 오는 best-path에 A가 포함되어 있기 때문에 무한대를 준다. 결과적으로 A는 무한대가 된다.
B의 입장에서 C는 무한대를 주고 A는 자신에게 오는 best-path에 B가 포함되어 있기 때문에 무한대를 준다. 결과적으로 B는 무한대가 된다.
C의 입장에서 D로부터 받는 정보는 없고 A와 B로부터 4를 얻게 된다. 원래는 A와 B가 자신에게 오는 best-path에 C가 포함되어 있어서 주지 못했지만 cycle때문에 3번과정에서 best-path에 포함된 직전노드가 바뀌었다. 때문에 4라는 값을 얻게 된다. 이때 best-path에 포함된 직전 노드는 A또는 B이다. 여기서부터 문제가 발생한다.
5번 과정
A와 B중 하나는 4번 과정의 C입장에서 best-path로 선택을 받고 하나는 선택을 못받기 때문에 둘중 어느 하나는 무한대가 아닌 5로 업데이트 될것이고 이때 best-path에 포함된 직전 노드는 C가 될것이다. (그림에서는 B)
위 과정이 계속 반복되다보면 모두 무한대가 되는 상황은 없고 계속 1씩 늘려가며 cycle에 포함된 노드들이 폭탄돌리기처럼 소유하는 상황이 발생한다.
이 값이 언젠가는 무한대가 될테지만 주구장창 기다릴 수만은 없으므로 본래 문제인 count-to infinity가 발생하게 된다.
링크-스테이트 방식과 디스턴스-벡터 방식을 알아보았다.
최종적인 둘의 차이는 다음과 같다.

어느 부분이라도 이해가 안된다면 이 글을 다시 읽자!
'컴퓨터 네트워크 > Computer Networking 정리' 카테고리의 다른 글
| 패킷 전송(Packet Delivery)_ARP (0) | 2021.11.25 |
|---|---|
| CH5 : Network Layer Control Plane (2) (0) | 2021.11.19 |
| CH4 : Network Layer (4) (0) | 2021.11.14 |
| CH4 : Network Layer (3) (0) | 2021.11.11 |
| CH4 : Network Layer (2) (0) | 2021.11.07 |



